MCP 맛보기

MCP가 뭘까
대 AI 시대를 살아가는 요즘 자연스럽게 MCP라는 단어를 많이 접하게 됩니다.
하지만 정작 MCP가 무엇인지에 대해서는 잘 모르는 경우가 많은데요.
그러한 사람이 바로 저였고, 자주 접하게 되는 이 MCP를 애써 외면하지 말고 이게 무엇이고, 어떻게 활용하는 것인지에 대해서 알아보는 시간을 가져보고자 합니다.
MCP는 보통 백엔드 관점으로 많이 알려져있고, 저 또한 그런 느낌으로 알고 있었는데, 이번에 MCP에 대해서 조금씩 알아가면서 프론트엔드 관점에서의 MCP에 대한 내용들도 접하게 됐습니다.
그래서 MCP에 대해서 조금씩 찾아보다보니 흥미로운 부분이 많아, 이번 포스팅에서 내용을 기록해보고자 합니다.
MCP(Model Context Protocol)
MCP is an open protocol that standardizes how applications provide context to LLMs. Think of MCP like a USB-C port for AI applications. Just as USB-C provides a standardized way to connect your devices to various peripherals and accessories, MCP provides a standardized way to connect AI models to different data sources and tools.
위 문장은 가이드 문서에 있는 MCP에 대한 소개 문장입니다. 한글로 번역해보면 다음과 같습니다.
MCP는 애플리케이션이 LLM에 제공하는 컨텍스트를 표준화하는 오픈 프로토콜입니다. MCP를 AI 애플리케이션의 USB-C 포트와 비유해보세요. USB-C는 다양한 주변 장치와 액세서리에 연결하는 표준화된 방법을 제공하듯이, MCP는 AI 모델을 다양한 데이터 소스와 도구에 연결하는 표준화된 방법을 제공합니다.
핵심은 MCP는 AI 모델을 다양한 데이터 소스와 도구에 연결하는 표준화된 방법을 제공합니다. 인 것 같습니다.
동시에 왜 MCP를 사용해야하는가에 대한 설명도 나와있는데요
MCP helps you build agents and complex workflows on top of LLMs. LLMs frequently need to integrate with data and tools, and MCP provides:
- A growing list of pre-built integrations that your LLM can directly plug into
- The flexibility to switch between LLM providers and vendors
- Best practices for securing your data within your infrastructure
위 문장은 MCP를 사용하면 LLM을 더 유연하게 사용할 수 있고, 데이터를 보호할 수 있다는 내용입니다.
MCP를 사용하는 이유
앞서 가이드문서에서 MCP를 사용하는 이유에 대해서 알아보았는데요. 조금 더 자세히 알아보도록 하겠습니다.
요즘 다양한 AI도구들이 나오고 있는데요. 이런 도구들을 사용하면서, 내 LLM이 내 말을 좀더 잘 이해했으면 좋겠다라는 생각을 자주 했었습니다.
실제로 LLM은 프롬프트 만으로도 충분히 잘 작동하는 경우가 많습니다. 하지만, LLM이 내 의도대로 보다 정확하게 동작하기 위해서는 정확하고 많은 양의 컨텍스트가 꾸준히, 그리고 구조적으로 주입되어야 합니다.
그렇다면.. LLM은 왜 컨텍스트가 필요할까요?
GPT에게 이것에 대해서 물어봤더니 아래와 같은 예시를 들어 설명해주었습니다.
예를 들어, 회사에서 사내 위키를 기반으로 답변하는 챗봇을 만든다고 해본다면
이때 LLM에게 우리는 이렇게 말합니다
"우리 회사 연차 정책 알려줘"
이 요청에 대해 LLM이 답변을 하기 위해서는 연차와 관련된 사내 문서를 이미 알고 있어야 합니다.
그러나, 이 사내 문서는 프롬프트 한 줄로 전달하기 어렵고, 크기도 클 수 있습니다.
그렇기 때문에, 우리가 할 일은 다음과 같습니다
- 사내 문서 내용을 적절히 분할
- 어떤 문서가 지금 질문과 관련 있는지 판단
- 그 일부를 LLM에게 동적으로 주입
이 과정을 컨텍스트 주입(Context Injection)이라고 합니다. 그리고 이것을 매번 직접 구현하는 것은 굉장히 번거롭고 복잡한 작업이지요..
그렇다면 LLM에 컨텍스트를 주입하는 기존 방법은 어땠을까요? 아래와 같은 과정을 거쳤을 겁니다.
- 클라이언트에서 사용자 질문을 감지
- 관련 데이터 검색
- 컨텍스트 + 질문을 조합해 프롬프트 생성
- LLM에게 요청
글로 봤을 때는 매우 합리적이고 단순해보이지만, 실제로는 그렇지 않습니다 프로젝트마다 구성 로직이 달라져야 하고, LLM 공급자가 바뀌면 요청 방식도 바뀌고, 데이터 보안 이슈도 생기고... 결국 각자 독자적인 연결 방식을 구현하느라 중복 개발이 발생하게 될 겁니다!
여기서 MCP가 등장합니다.
LLM과 데이터를 어떻게 연결할 것인가! 를 하나의 표준으로 묶어주는 것이 MCP의 역할입니다.
- 프롬프트에 어떤 컨텍스트를 넣을지 자동화
- LLM 공급자(GPT, Claude 등)가 바뀌어도 동일한 구조 사용 가능
- 데이터 접근 로직을 분리해서 보안성을 유지
- 컨텍스트와 도구(tool)를 함께 연결할 수 있음
정리하자면,
- LLM은 똑똑하지만 문맥을 모르면 답변을 잘 못한다
- 문맥을 주입하는 구조는 복잡하고 반복적
- MCP는 이런 연결을 표준화하고 간소화 해주는 역할
그래서 MCP를 도입하면 복잡한 컨텍스트 구성 로직을 단순화하고, 다양한 데이터와 LLM을 안정적으로 연결할 수 있게 해줍니다.
LLM에 대해서 잘 모르는 제가 이해한 바로 비유해서 설명해보면
- LLM은 똑똑한 비서!
- MCP는 요청한 업무에 필요한 자료나 도구를 자동으로, 쳬계적으로 전달해주는 도구! 비서의 비서! 라고 저는 이해했습니다.
MCP의 구조
가이드에서 제시하는 보편적인 MCP의 구조는 다음과 같습니다.
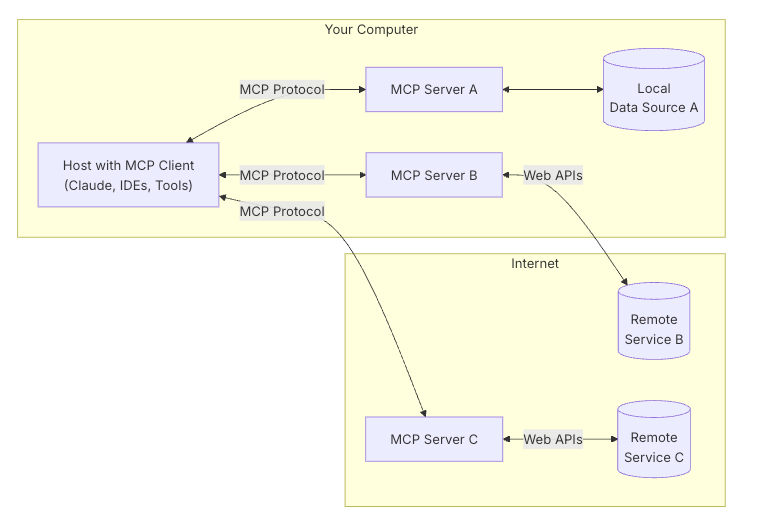
- MCP 호스트(MCP Hosts): Claude Desktop, IDE, 또는 MCP를 통해 데이터에 접근하고자 하는 AI 도구와 같은 프로그램들
- MCP 클라이언트(MCP Clients): 서버와 1:1 연결을 유지하는 프로토콜 클라이언트
- MCP 서버(MCP Servers): 표준화된 Model Context Protocol을 통해 각각 특정 기능을 노출하는 경량 프로그램
- 로컬 데이터 소스(Local Data Sources): MCP 서버가 안전하게 접근할 수 있는 내 컴퓨터의 파일, 데이터베이스, 서비스 등
- 원격 서비스(Remote Services): MCP 서버가 연결할 수 있는 인터넷상의 외부 시스템(API 등)
MCP 사용해보기
어느정도 MCP에 대해서 알게 된 것 같습니다.
그렇다면 실제로는 어떻게 사용되는지 한번 알아보도록 하겠습니다.
제가 사용하는 AI 에디터인 Cursor.ai 를 기준으로 살펴보겠습니다.
MCP 관점에서 Cursor는 Claude, GPT-4, Mixtral 등을 백엔드로 사용하는 AI 기반 코드 에디터 입니다.
그 자체로 MCP 호스트 역할을 하는 것이지요!
내가 작성한 코드를 읽고 AI에게 질문을 할 수 있는 인터페이스를 제공합니다!

하지만.. 위와 같이 질문이 명확하지 않다면..! 내가 딱 원하는 답변을 얻지 못하는 경우가 빈번합니다
위처럼 Cursor는 자체적으로 LLM모델을 선택할 수 있고, 또한 컨텍스트를 주입할 수 있습니다.
예를 들어, Claude 모델을 선택하고 Cursor에게 질문을 하나 해보겠습니다
"이 함수를 리팩토링해줘!!"
이때 Claude는 단순히 질문 텍스트만 받는 게 아니라,
Cursor가 MCP 클라이언트 역할을 하며 다음과 같은 컨텍스트를 함께 전달합니다
-
현재 열려 있는 파일의 전체 코드
-
최근 수정된 코드 범위
-
관련된 import 파일 내용
-
프로젝트 설정 파일 (예: package.json, tsconfig.json)
-
터미널 로그나 테스트 결과 등
이런 컨텍스트가 MCP를 통해 Claude에게 구조화된 형태로 전달되기 때문에, Claude는 더 정교한 응답을 해줄 수 있습니다.
돌이켜보면 Cursor를 사용하는것 자체가 MCP 를 사용하는 상태라고 볼 수 있습니다!!

MCP가 뭐야뭐야 어떻게 사용하는거야 호들갑을 떨었지만 사실은 이미 이런 형태로 사용하고 있었던 것이지요!
프론트엔드에서의 MCP
MCP에 대해서 알아보면서 가장 관심있게 보고 있는 주제입니다. 사실 오늘 이 포스트를 작성하게 된 가장 큰 이유가 바로 이 내용이었습니다.
MCP에 대해 궁금함을 해소하고자 구글링을 하다보면 감사하게도 다양한 프론트엔드 관점에서의 MCP 활용 예시들이 나오는데요!
그 중에서 맘에 쏙드는 예시를 하나 따라해보면서 프론트엔드에서 MCP를 활용하는 방법을 알아보면 좋을 것 같습니다!!
제 마음에 쏙 들었던 것은 바로 Figma MCP를 활용하는 방법이었습니다!!
이제는 대체 불가능한 툴이 되가는 Figma..! 이전부터 피그마를 사용해오고 있지만 아직 사이가 어색하긴 한데요..
MCP에 대해 공부하는 겸 이참에 조금 더 친해져보는 일방적인 시간을 가져보도록 하겠습니다!
Figma MCP를 활용해 UI 컴포넌트 개발하기
이전 회사에서 디자인 시스템을 도입함과 동시에 피그마를 사용하게 됐었습니다
당시에 동료 개발자들과, 피그마를 처음 접하면서 리액트 컴포넌트를 자동으로 만들어준데!! 라는 말에 혹해서 이것저것 시도해봤던 기억이 납니다.
하지만, 당시에 피그마를 리액트 컴포넌트로 가져오려면 디자이너가 디자인시스템을 피그마에서 구현할 때, 우리가 생각하는 구조와 일치하게 만들어야 하는 등 신경써야 할 것들이 많았습니다
당시 디자이너 분과 피그마의 올바른 사용법과 디자인 시스템, 디자인 토큰 등에 대해 수많은 토론..을 해야했던 기억이 납니다.
결론적으로는 자동적으로 리액트 컴포넌트를 만들어주는 것은 어려웠습니다. 우리가 타협한 결과에 맞춰서 우리가 구현하고, 조금의 자동화를 섞는 것이 당시의 한계였습니다.
하나의 버튼 컴포넌트를 탄생시키기까지 소요되는 자원이 너무 크고, 그것을 회사가 기다려주기엔 너무 비용이 컸던 것으로 기억합니다.
그러나!!
이제는 피그마 MCP를 활용해 프론트엔드 개발자의 숙제 중 하나인 UI 컴포넌트를 효율적으로 개발하는 방법을 소개해보려 합니다.
바로 Figma-Context-MCP를 사용해 그 피그마와의 간극을 좁혀보는 것입니다!!!!
1. Cursor 와 Figma MCP 연결하기
Figma-Context-MCP는 Cursor와 같은 AI 에디터를 피그마와 연결해주는 MCP로, 피그마의 노드 주소를 프롬프트에 추가하면 UI를 인식해 코드로 전환할 수 있습니다..!
framelink.ai 에서 영상과 함께 알아볼 수 있습니다.
1. 설치 및 연결
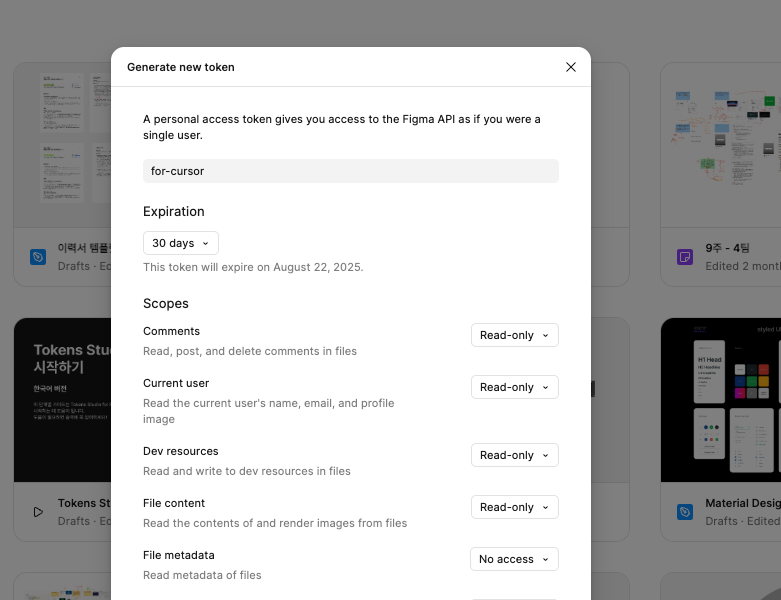
먼저 피그마 토큰이 필요합니다
피그마 -> settings -> security -> personal access tokens 에서 토큰을 생성합니다

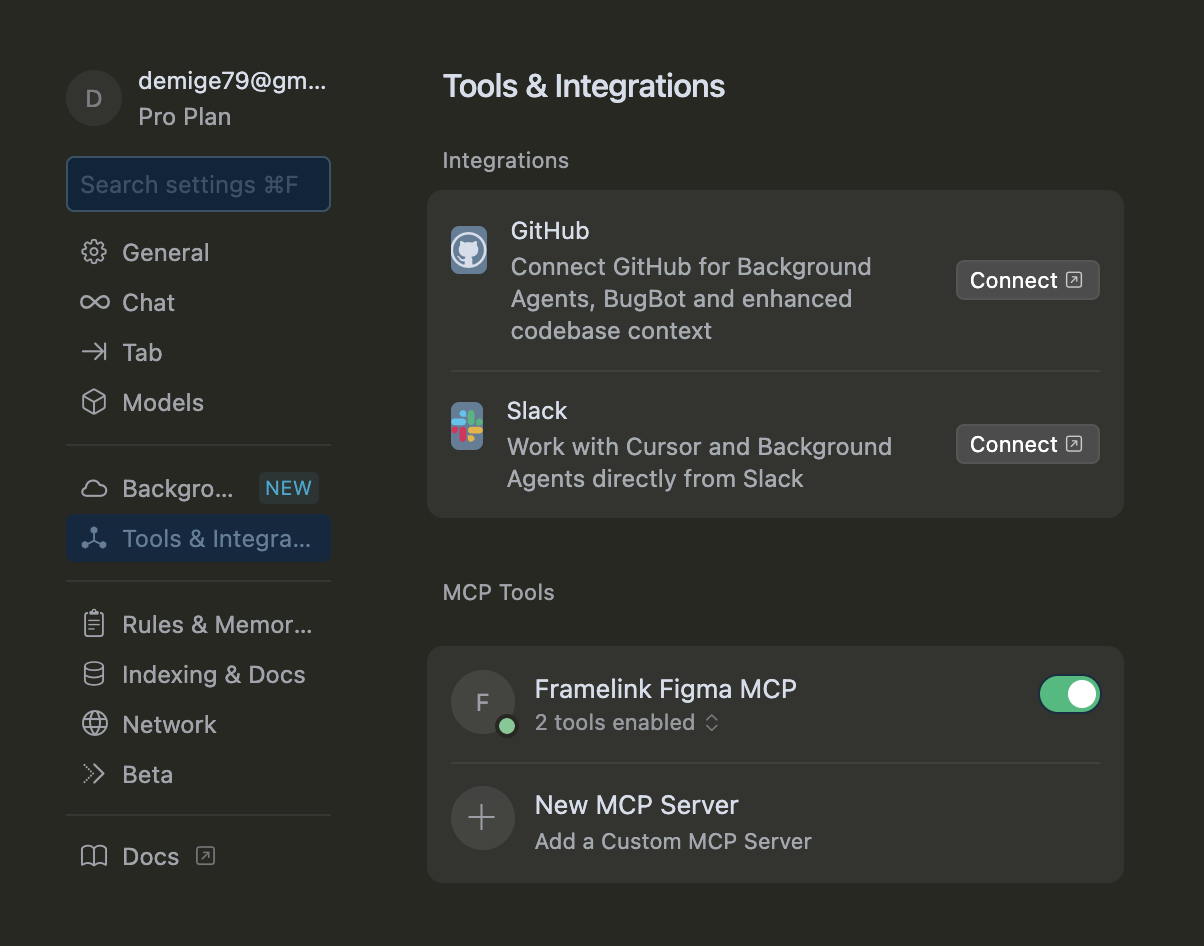
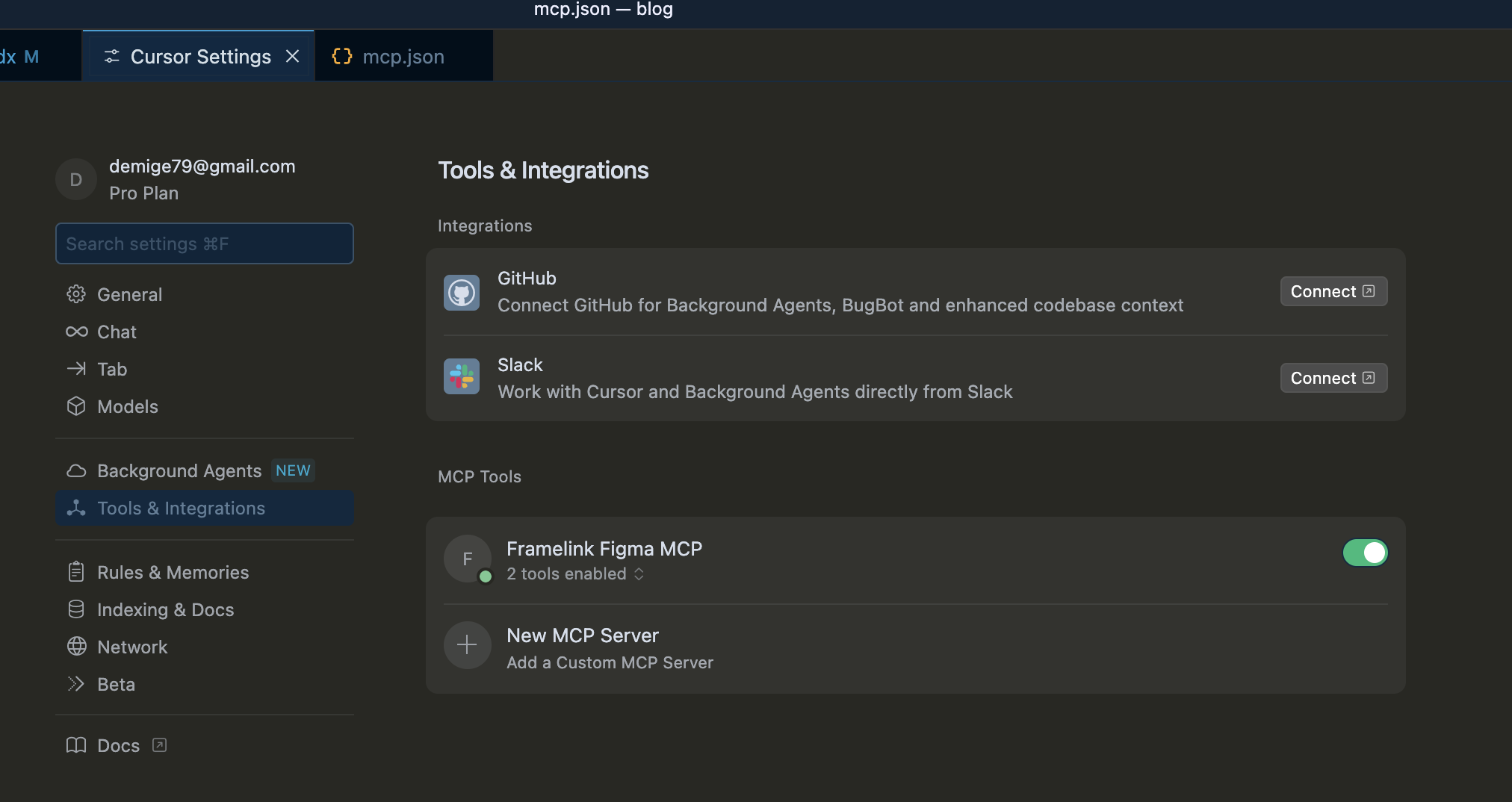
다음으로는 Cursor 설정에서 MCP 서버를 추가해줍니다
cursor -> 기본설정 -> Cursor Settings -> Tools&Intergrations -> MCP Tools -> New MCP Server
{
"mcpServers": {
"Framelink Figma MCP": {
"command": "npx",
"args": [
"-y",
"figma-developer-mcp",
"--figma-api-key=피그마_액세스_토큰",
"--stdio"
]
}
}
}위와 같이 서버를 추가하고 앞서 발급했던 토큰 정보를 기입해주면 됩니다.
정상적으로 연결됐다면 초록불이 나타납니다..!
2. Figma MCP로 컴포넌트 개발 뚝딱하기
설정이 완료됐다면, 테스트를 위해 Figma에 Material UI의 피그마 템플릿을 통해 간단한 컴포넌트를 추가해보겠습니다
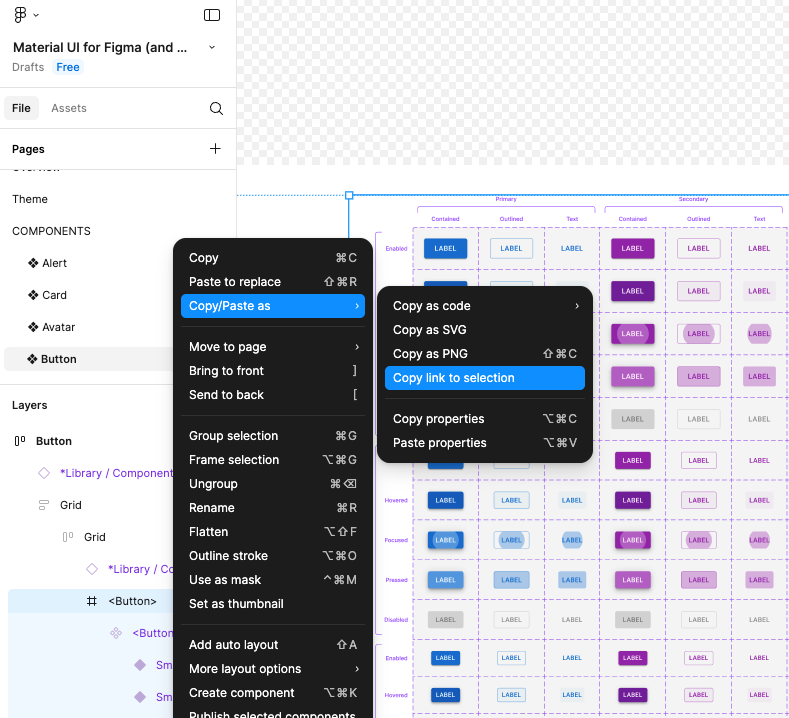
이미지와 같이 노드정보를 가져오고,
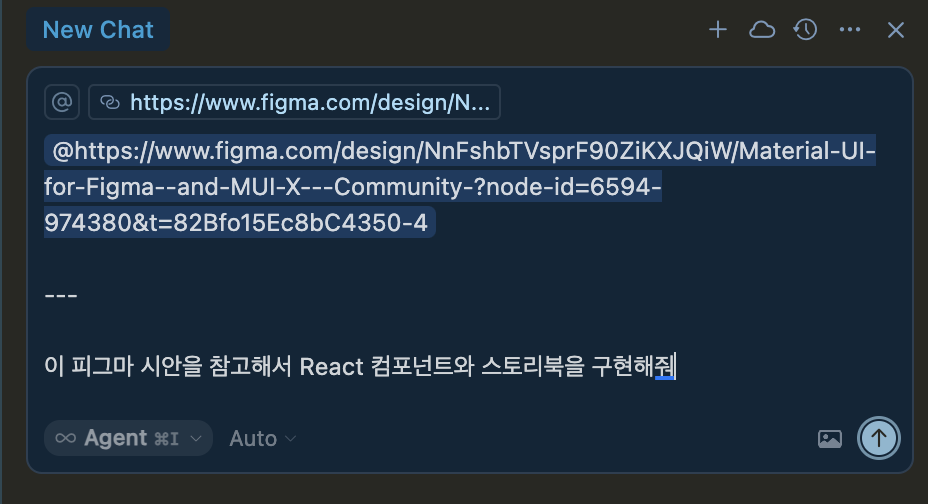
커서에게 노드 정보를 전달하고 원하는 작업을 명령하면 됩니다!!

그렇게 되면 아래와 같이 생성된 버튼 컴포넌트를 확인할 수가 있습니다..!
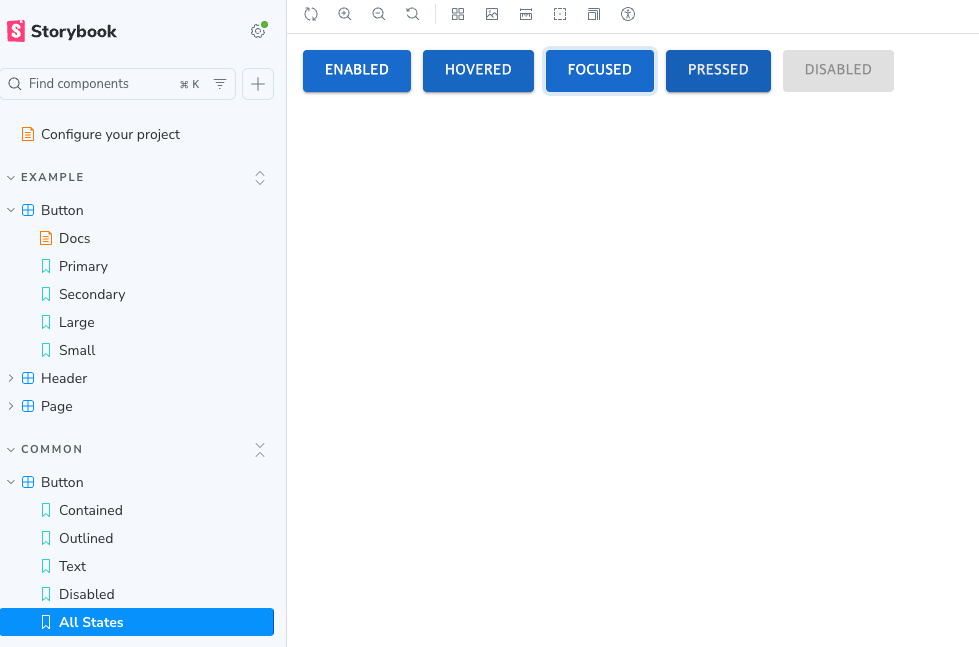
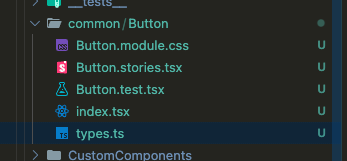
짧게 알아본 것만으로도 참으로 흥미롭지 아니할수가 없습니다..!
이전에 피그마로 꿈꿨던 현실과 가까워진 것 같은 기분이 듭니다.
물론 실무에서 사용하려면 더 신경써야 할 부분들이 있겠지만
디자인 시스템이 잘 구축되어있고, 피그마 디자인이 정해진 규칙을 따르고 있다면
충분히 실무에서도 사용해봄직하지 않나요..?
MCP 도입시 주의할 점
앞서 알아본 것처럼 MCP는 프론트엔드 개발에서도 중요한 역할을 하고 있고, 앞으로가 더 기대되는 기술임에 틀림 없습니다
하지만! 아직 부족한 점도 있고 특히나 주의해야 할 부분이 있습니다
1. 데이터 보안과 권한 관리
MCP는 LLM에게 컨텍스트를 전달하기 위해 내부 데이터에 접근합니다
이러한 과정에서
- 의도하지 않은 정보 유출은 없는가?
- 민감한 정보는 없는가?
- 권한 제어가 가능한가?
등 사용자가 관리해야 할 부분이 존재합니다
2. LLM 공급자에 따른 대응
MCP는 다양한 LLM 공급자를 유연하게 교체할 수 있도록 설계되어 있습니다. 하지만 실제로는 Claude, GPT-4, Mixtral 등 각 모델마다 응답 방식, 제한 사항, 요금 정책이 다릅니다. 예를 들어, Claude는 context window가 넓지만 tool 사용에 제약이 있을 수 있고, GPT-4는 context 처리량이나 요청 지연(latency) 이슈가 발생할 수 있습니다. 모델에 따라 RAG 구조에 더 적합한 경우도 있고, agent task 처리에 강점을 보이기도 합니다. MCP는 하위 호환성을 제공하지만, 실제 사용하는 모델에 따라 context pack 구성이나 툴 호출 전략을 달리 설계하는 것이 필요합니다.
3. 개발·배포 환경과의 통합
MCP는 개발자 로컬 환경이나 엔터프라이즈 내부 인프라에서 동작합니다. 이 과정에서 다음과 같은 실무 환경 요소와의 통합 이슈가 발생할 수 있습니다.
- 로컬 dev server와의 포트 충돌
- 에디터(예: Cursor)나 IDE별 MCP 클라이언트 설정 차이
- CI/CD 환경에서의 MCP 테스트 전략 미비
- 사내 프록시 또는 VPN 환경에서의 네트워크 제한
초기에는 개인 환경에서 실험적으로 도입한 뒤, 구성 요소를 점진적으로 팀 개발 환경에 적용하는 것이 좋아보입니다.
마치며
최근 포스트를 통해 Cursor.ai와 MCP 등 AI 도구들을 통한 개발에 대해서 조금씩 알아보고 있습니다
때마다 참 신기하면서도 묘한 것이
앞으로 어떤 자세로 개발을 해야하는지에 대해서 다시 생각하는 계기가 되는 것 같습니다
새로운 기술과 도구의 도입과 교체가 빠르게 이루어지는 현재 시장에서
작은 시야에 갇히지 않고 유연하게 대처할 수 있는 자세를 가져야겠습니다..!
물론 새로운 기술에 무조건 혹하지 않고 장단점을 명확히 구분할 줄 아는 그런 개발자가 되보겠습니다
또 다른 주제로 돌아오겠습니다.
그럼 이만!